What is Stable-Diffusion
Here is the description on GitHub.
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database.
In a word, it is a tool to generate images.
Quick start
As an exceptional open-source project, numerous developers actively contribute and share their usage approaches. In this regard, I will present three methods for utilizing it. However, if you are a beginner, I highly advise skipping the first method and opting for the second method instead.
Directly use Web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
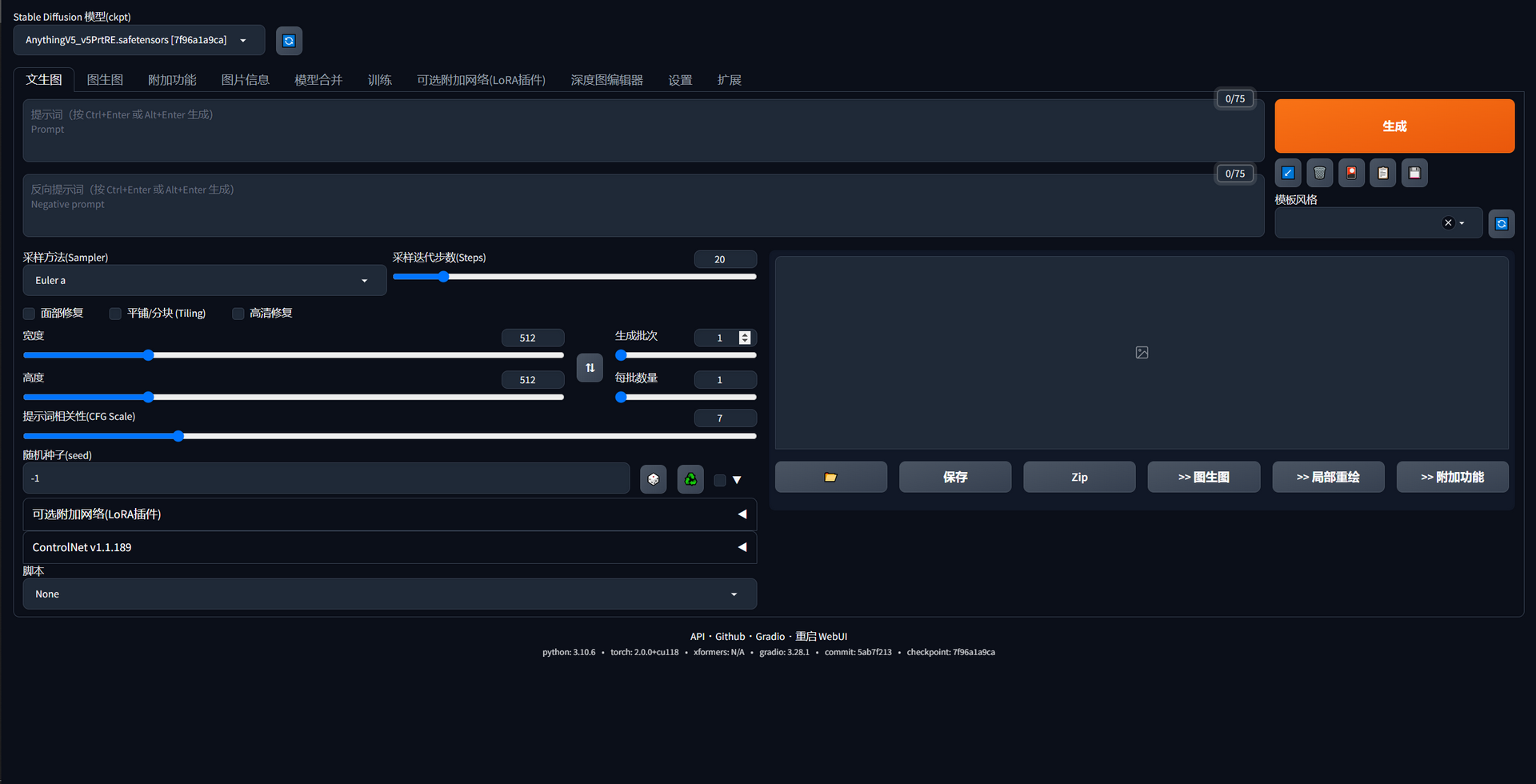
The most popular approach to using Stable-Diffusion is through its user-friendly UI and the availability of numerous useful plugins. The project’s website provides a comprehensive guide on installation and execution, which I have quoted below for your reference:
Installation and Running
Make sure the required dependencies are met and follow the instructions available for both NVidia (recommended) and AMD GPUs.
Alternatively, use online services (like Google Colab):
Automatic Installation on Windows
- Install Python 3.10.6 (Newer version of Python does not support torch), checking “Add Python to PATH”.
- Install git.
- Download the stable-diffusion-webui repository, for example by running
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git.- Run
webui-user.batfrom Windows Explorer as normal, non-administrator, user.Automatic Installation on Linux
- Install the dependencies:
# Debian-based: sudo apt install wget git python3 python3-venv # Red Hat-based: sudo dnf install wget git python3 # Arch-based: sudo pacman -S wget git python3
- Navigate to the directory you would like the webui to be installed and execute the following command:
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
- Run
webui.sh.- Check
webui-user.shfor options.Installation on Apple Silicon
Find the instructions here.
By following these instructions, users can easily get started with Stable-Diffusion Web UI and leverage its full potential.
Use Integration Package and Starter
Thanks to the contributors of 绘世, the threshold of AI painting is further lowered. Following the video made by 秋葉aaaki, you will get the integration package and draw your first AI image. Be careful, it is only available on Windows.
Recommended for Windows
- Use git tool to get the original Web UI:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitorgit clone https://gitcode.net/overbill1683/stable-diffusion-webui.git. - Download the Starter shared on Bilibili, and then move it to the root path of
stable-diffusion-webui.
The problems I encountered
Here are a few problems I encountered previously. I hope these problems prove useful.
Python, Torch, and CUDA version
These 3 things have a serious version limitation. I got the following version match list from https://pytorch.org/blog/deprecation-cuda-python-support/.
| PyTorch Version | Python | Stable CUDA | Experimental CUDA |
|---|---|---|---|
| 2.0 | >=3.8, <=3.11 | CUDA 11.7, CUDNN 8.5.0.96 | CUDA 11.8, CUDNN 8.7.0.84 |
| 1.13 | >=3.7, <=3.10 | CUDA 11.6, CUDNN 8.3.2.44 | CUDA 11.7, CUDNN 8.5.0.96 |
| 1.12 | >=3.7, <=3.10 | CUDA 11.3, CUDNN 8.3.2.44 | CUDA 11.6, CUDNN 8.3.2.44 |
First, make sure that your Python version is 3.10.6. You can use python -V to have a check. If you are a beginner in Python and your Python version is incorrect, please just uninstall your old Python and download Python3.10.6 from its website.
Then, download the matched CUDA toolkit from the NVidia website.
C Drive Usage
Python will install all libraries on the C drive by default, so it is very easy for Python to take up almost all the space in your C drive. Although the guide on the Web UI website has recommended that users should use venv, there is no guarantee that everyone will follow it either. If you have already faced the problem, please uninstall your Python and reinstall it on another drive.
Slowly pip install
This is a common problem in mainland China. The reasons for that are not safe to talk publicly. Well, that is not an important thing. What we should do is to set a pip mirror in China first instead of directly using it.
I recommend using the Tsinghua mirror. Of course, other mirrors are also fine.
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
Basic introduction to WebUI
To make the passage shorter and easy to understand, I will use the 绘世 Starter in the following essay, which is exactly what I am using now. Before reading the rest post, make sure you have already generated at least one image with SD-WebUI. Let’s start!
Stable-Diffusion Checkpoint
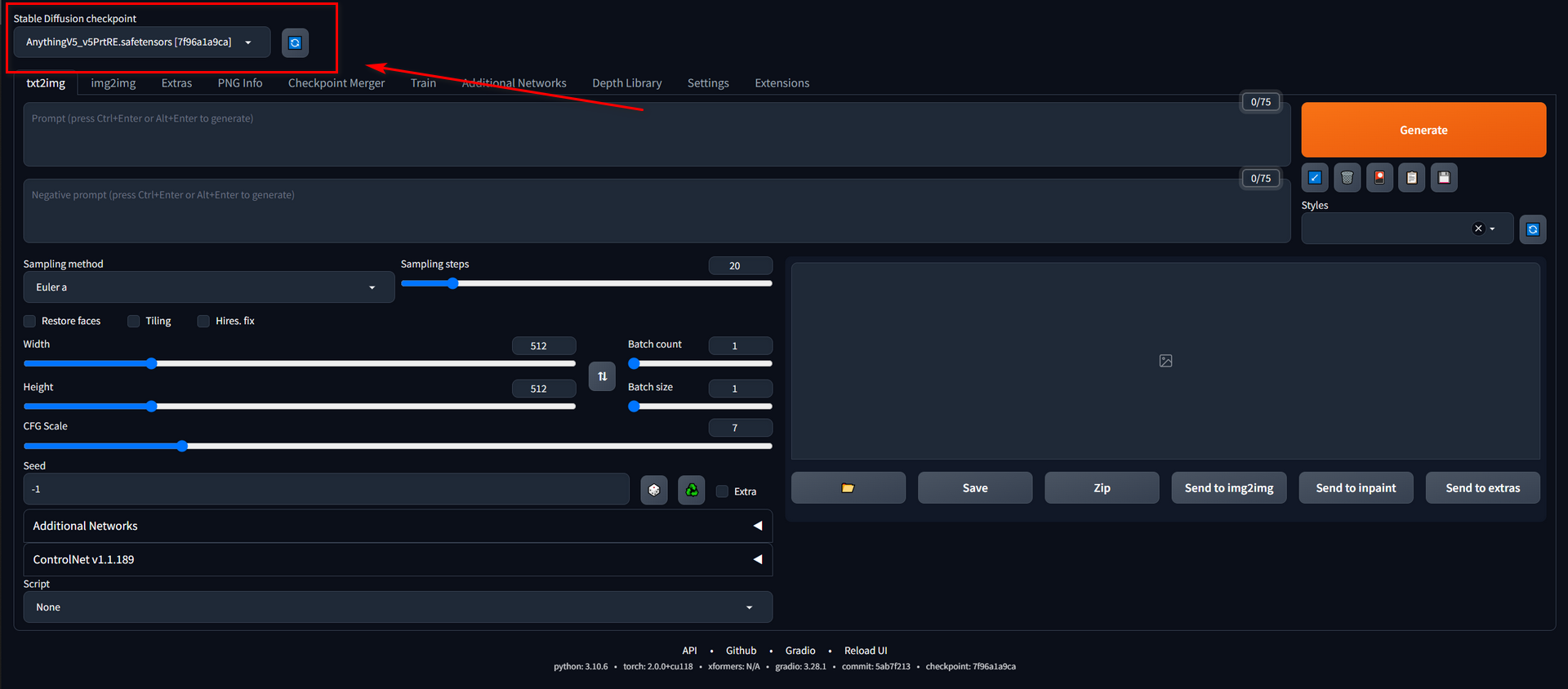
The checkpoint model, also named the big model, is the base of your image. The style of the output image is profoundly influenced by this factor, much like the way different chefs from various countries can create entirely distinct dishes using the same ingredients.
If you have followed SD (Stable-Diffusion) for a long time, you may have heard about the NovelAI model, which had a great performance on anime drawing. Besides, popular anime models also include Anything, pastelMixStylizedAnime, counterfeit, and so on. By the way, I will not talk about the reality model, and please do not ask me why. Here is a simple contrast between the models above.

It is easy to see the difference between them. Generally, I will choose Anything V3 to test the prompts first. Based on my personal experience, Anything V3 demonstrates exceptional performance across various fields, making it of significant importance. Besides, Anything V5 can understand your prompts better, but that does not mean that it can produce a better image. PastelMixStylizedAnime sometimes can give me surprise, but in exchange, it is harder to control the results. About the counterfeit model, compared to the Anything model, it has a certain smear and provides a different anime style.
Except for the models I have listed above, there are also many checkpoint models in CIVITAI and HuggingFace.
Prompts
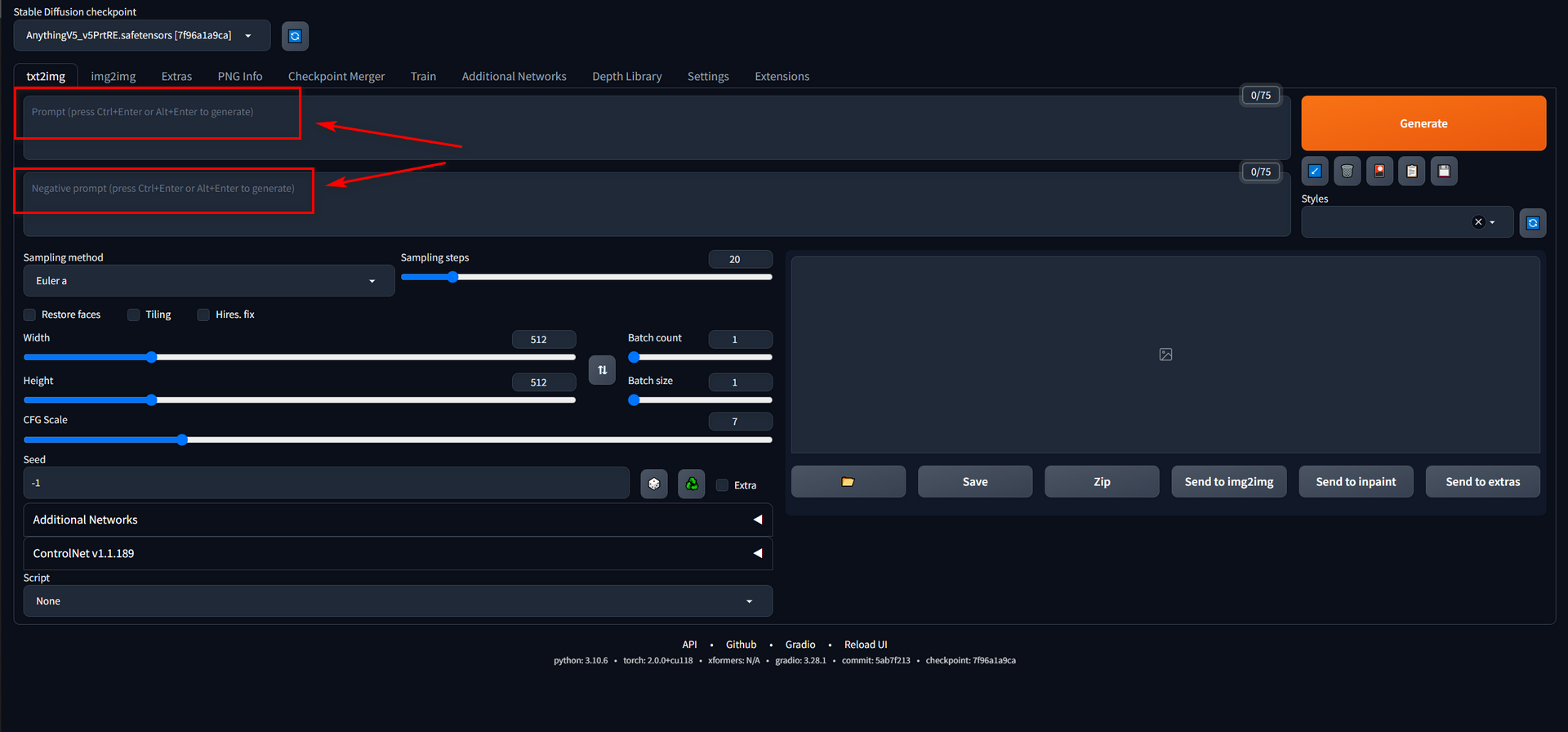
Drawing another analogy to cooking, prompts can be likened to the raw ingredients used in food preparation. Additionally, prompts also play a crucial role in determining how these ingredients are handled and processed.
As beginners, it can be challenging to effectively convey our imagination to AI or even have a clear vision in the first place. How to enter the prompts can be a huge proposition and many people work on it. So we can learn from the prompts shared by others or just copy them into the input box. In the “small tools” part of the starter, there are some image-sharing websites and we can get both positive and negative prompts there.
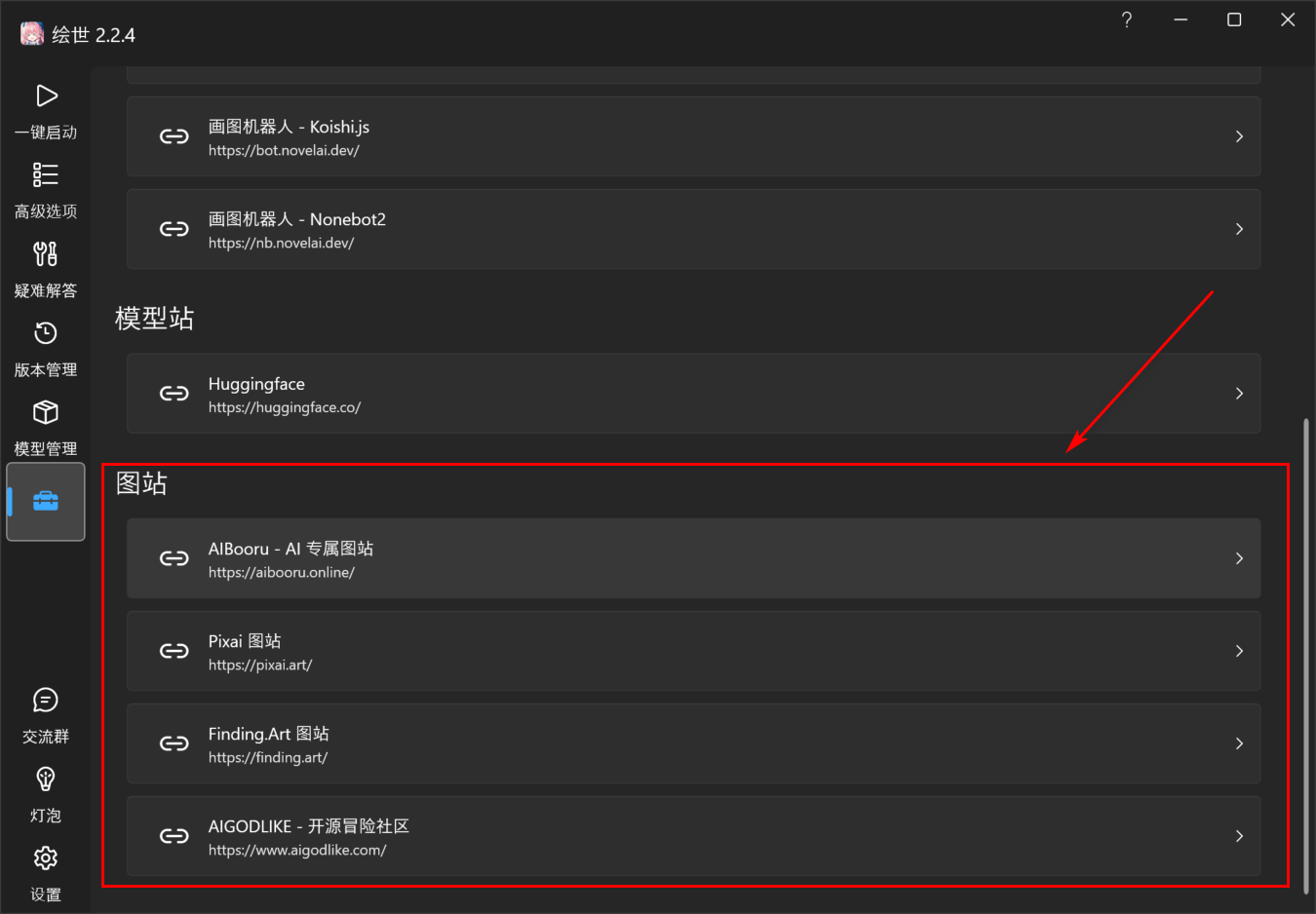
Be careful “AIBooru” has tons of NSFW images!!!
Take Pixai as an example. Visit its website and select one image you like.

Click the image and you will get its detail, including prompts, sampling stops, sampling method, etc.
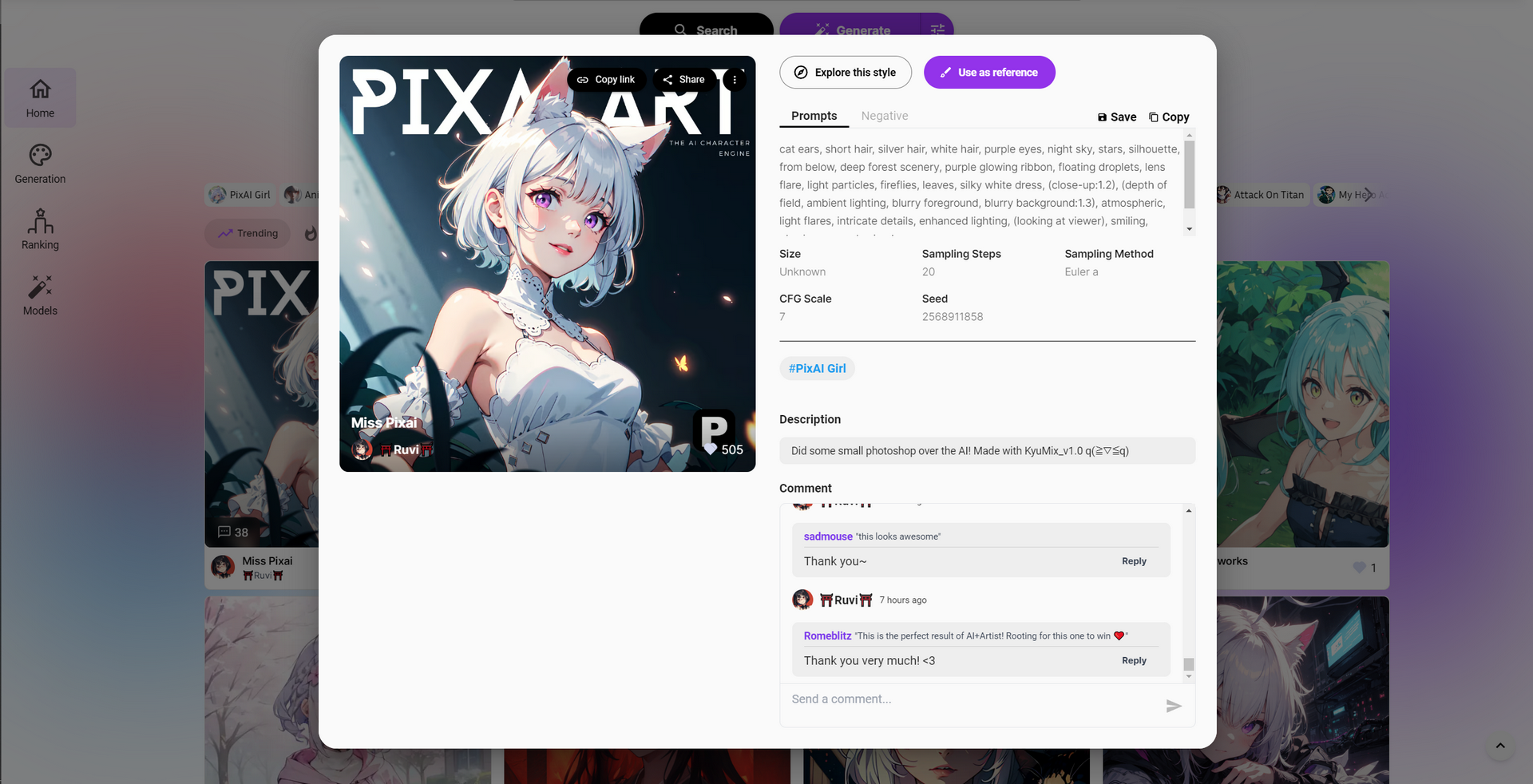
Just copy the prompts into your prompts, copy the negative prompts into your negative prompts, and start to generate an image.
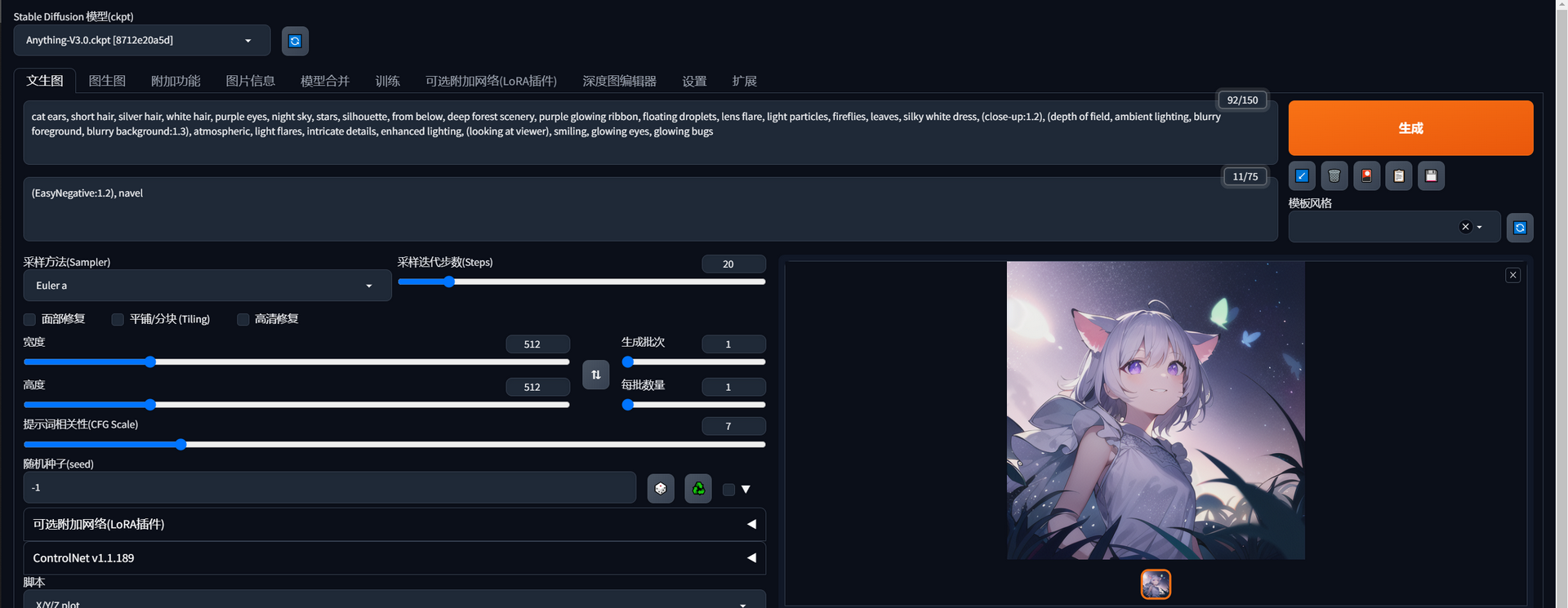
That is all! You may get a good image now.
Finally, if you want to learn more about prompts, you can read the following articles:
Sampling methods
Expand the select box of “Sampling method”, you may get confused about which one should I choose.
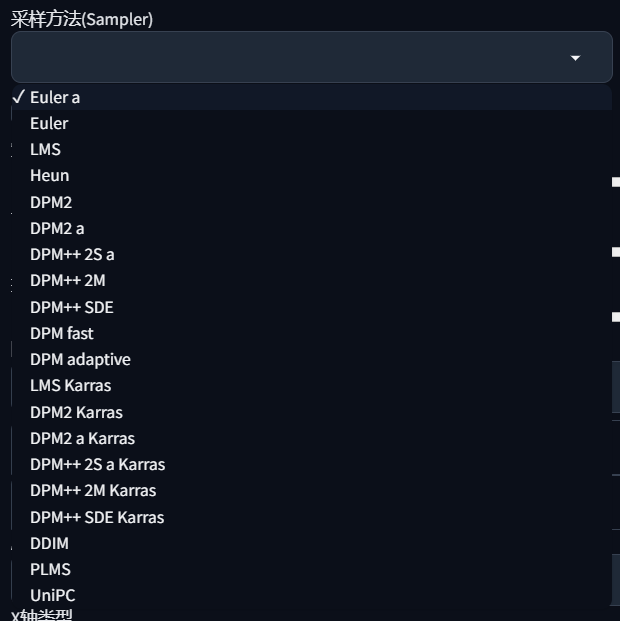
Each of them will return a similar result with a little difference, but according to my subjective feeling, I consider that Euler a and DPM++ 2M Karras are very fast on the basis of stable production of high-quality images.

You may notice that some samplers have the letter “a” appended to their names, indicating they are ancestral samplers. To ensure consistent results with the same parameters, it is recommended to use the sampler without the letter “a”. Of course, if you need to generate different images each time, please choose the one with “a” suffix (some without “a” may also be ancestral sampler).
Sampling steps
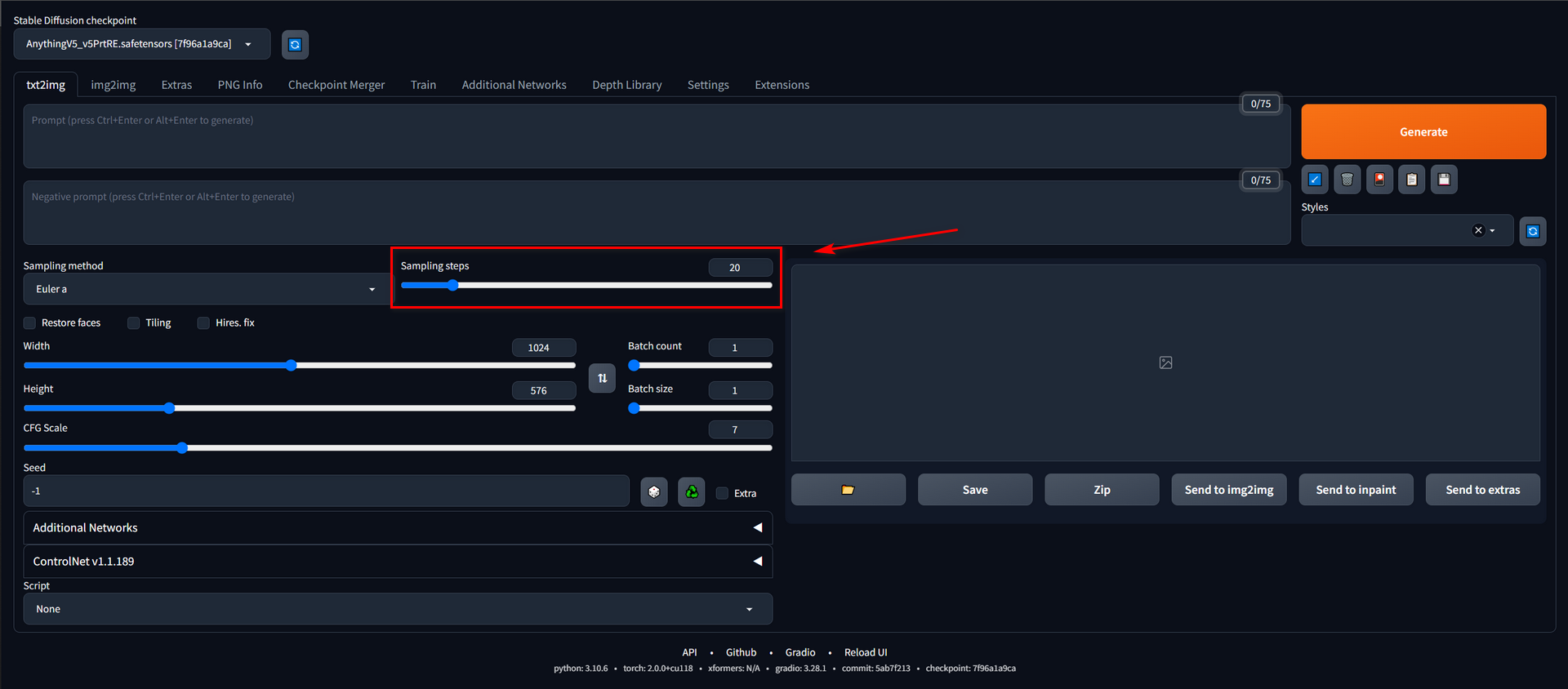
This is one of the most easily understood parameters. Higher steps, longer generation time, and maybe better results. The only thing we need to know is the sweet point of the number of sampling steps for different sampling methods.
| Sampling method | Sampling steps |
|---|---|
| Euler a | 20-35 |
| Euler | 20-35 |
| DPM2 | 20-40 |
| DPM2 a | 25-40 |
| DPM++ 2M Karras | 20-30 |
| DDIM | 30-45 |
Width & Height
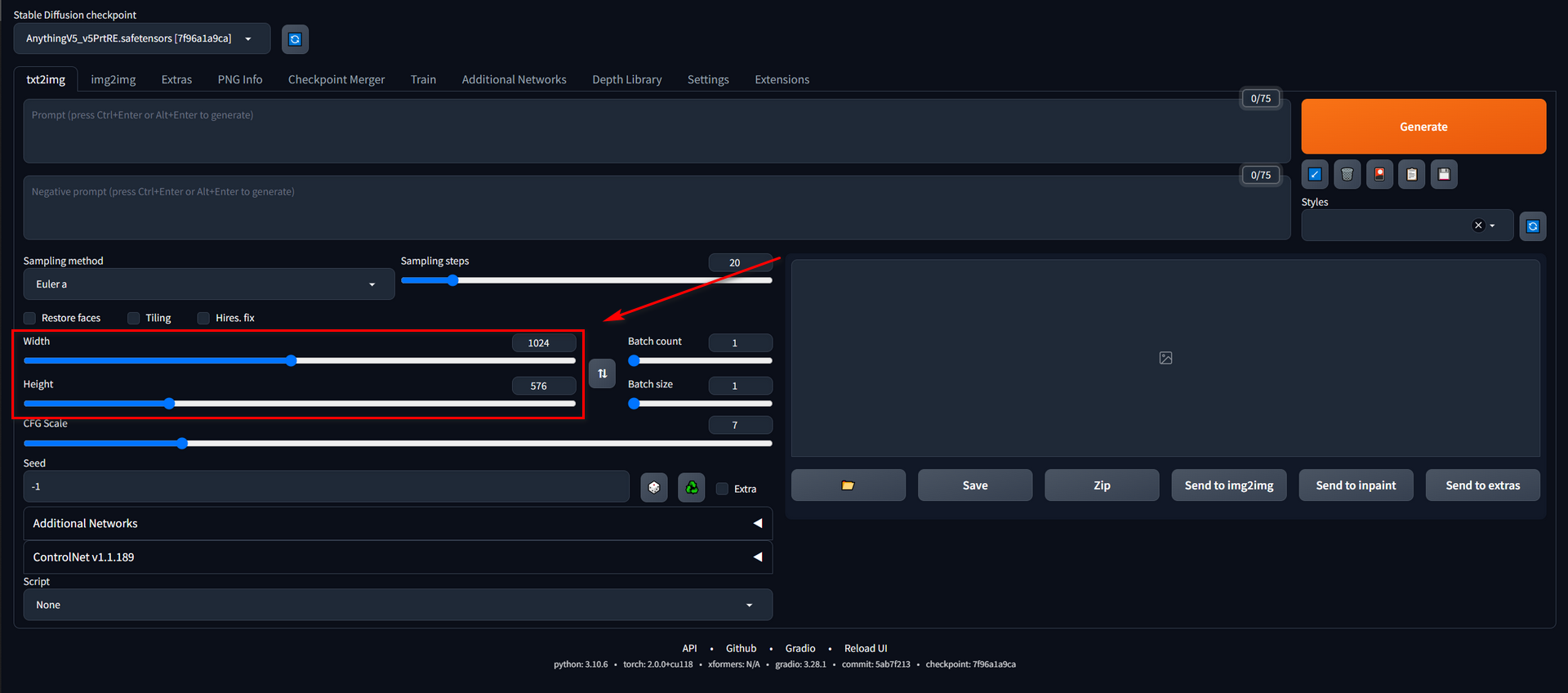
The higher the resolution means higher the GPU memory usage. I usually use 1024/*576 (16:9) or 640/*640 (1:1).
CFG Scale
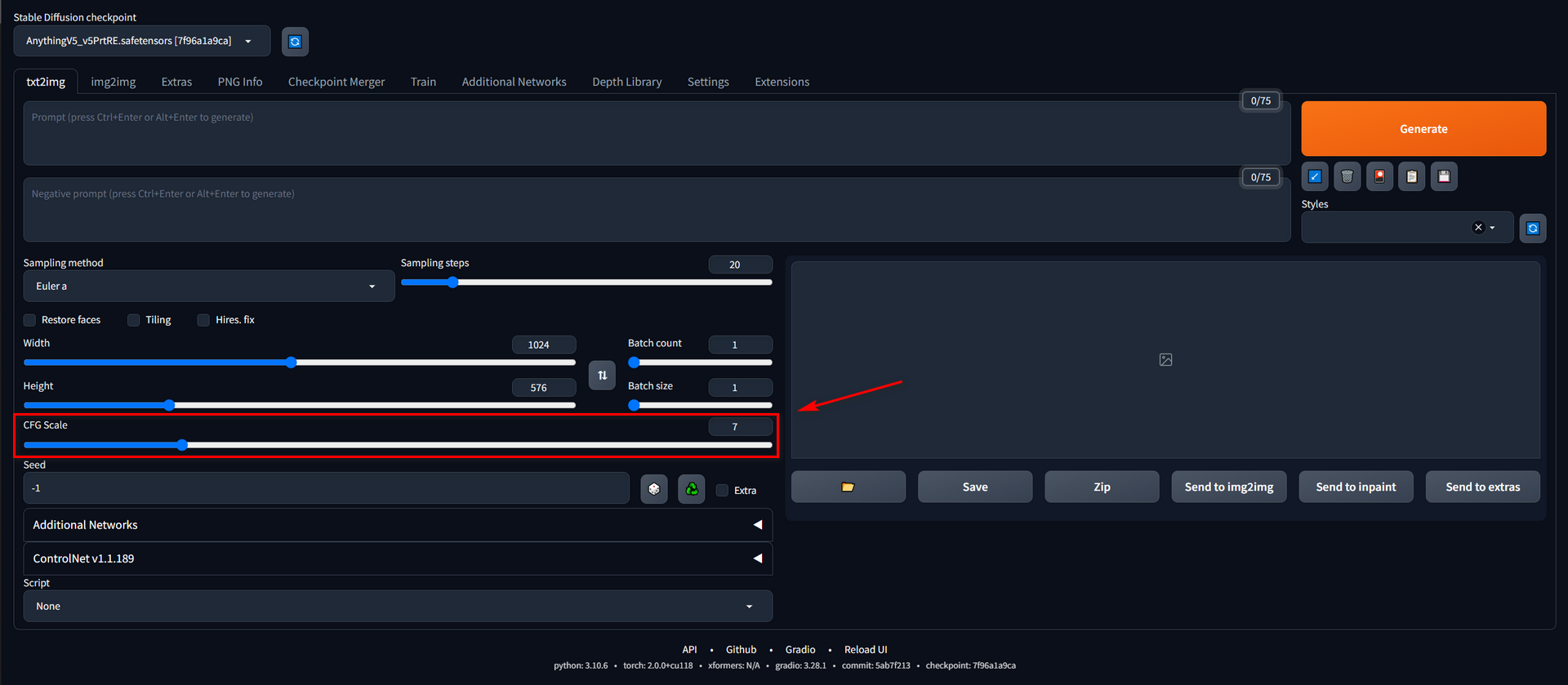
To grant the AI more creative freedom, it is advisable to set a lower value for CFG Scale. Conversely, if you desire more controlled outputs, a higher value should be selected. As a general guideline, 7 is considered a balanced point, and I recommend setting the value between 5.5-13 for optimal results.

Seed
This is the only parameter that has a huge impact on the picture but you can’t predict the output. Just set it to -1 unless you want to generate the same image shared by others.
Some other things I am using
In this part, I will share some plugins and other functions I am using now.
Embedding
It works like a collection of tags, and it can be directly used in prompts.
LoRA (Low-Rank Adaptation)
Seeing a familiar painting makes us recognize the subject or style that we are familiar with. It is also workable on Stable-Diffusion with LoRA. We can use LoRA to partly influence the output image, such as the character’s face, the drawing style, and so on.
Generally, I prefer using LoRA to designate the characters I like. It is worth mentioning that many characters already have their LoRA models available online, such as CIVITAI.
ControlNet
It is a very powerful additional net. Just as its name suggests, ControlNet enables precise control over the composition of images or the poses of characters within the frame. Here, I want to recommend an article: ControlNet v1.1: A complete guide, which is a very detailed and logically clear guide.
Inpaint
We often come across an almost perfect picture that has great composition and beautiful colors, but the faces or hands of the characters inside look abnormal. In such cases, we need the Inpaint feature, which allows us to repaint a portion of the image. Through multiple iterations of repainting, we can ultimately obtain a version where the flaws have been repaired.
For example, this image features a visually appealing pattern and composition, but the characters’ facial expressions are not pleasing, and, most importantly, there is an extra leg drawn.

These are the processes (including img2img) of the Inpaint:

And finally, we get this image.

Extras
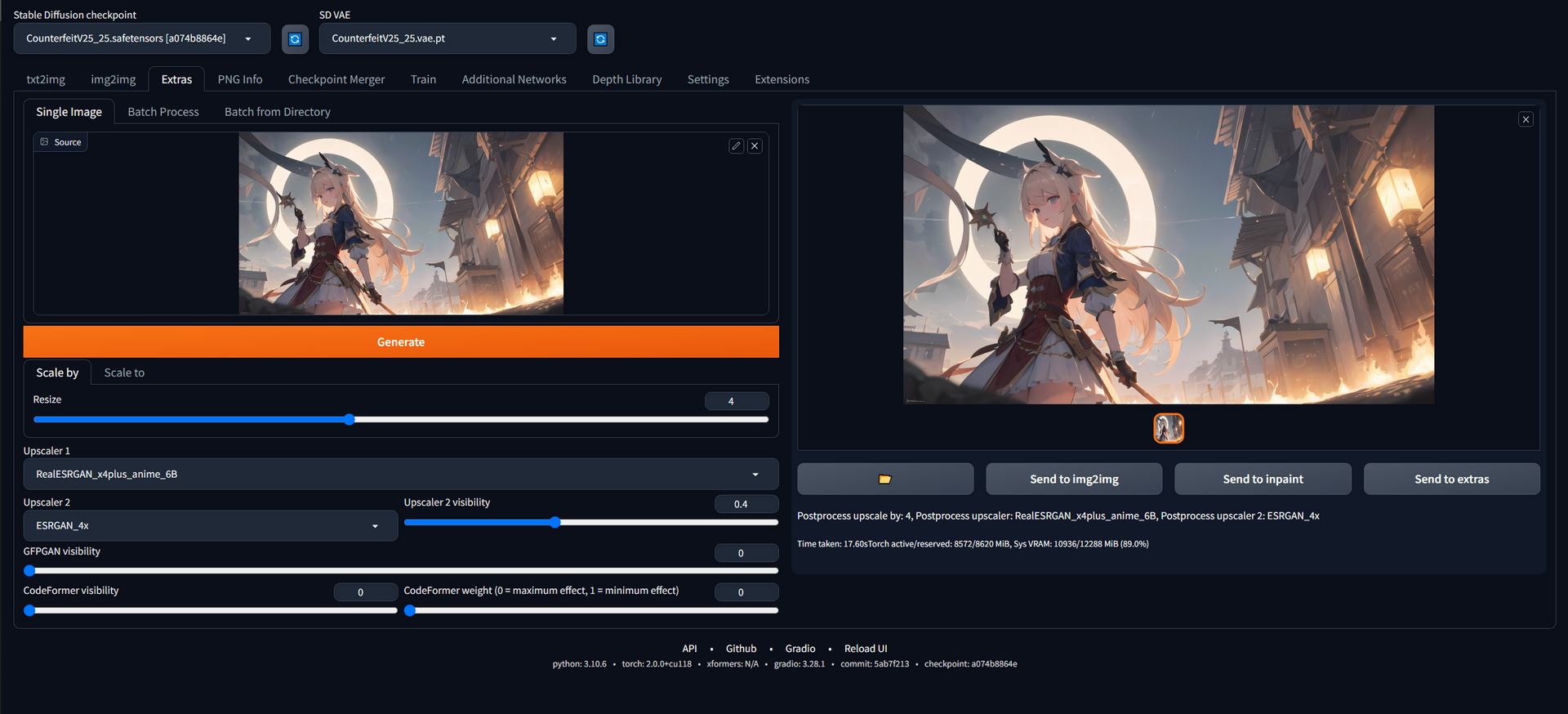
Generally, we can not directly get a high-resolution image because of the VRAM limitation and the speed. So, we usually use other methods to get a high-resolution image, like extras. With the use of the appropriate models, we can obtain super-resolution images that are not inferior to the original ones. In general, I prefer using the “ESRGAN_4x” or “Real_ESRGAN_4xplus_anime_6B” models, as they provide excellent support for anime images.
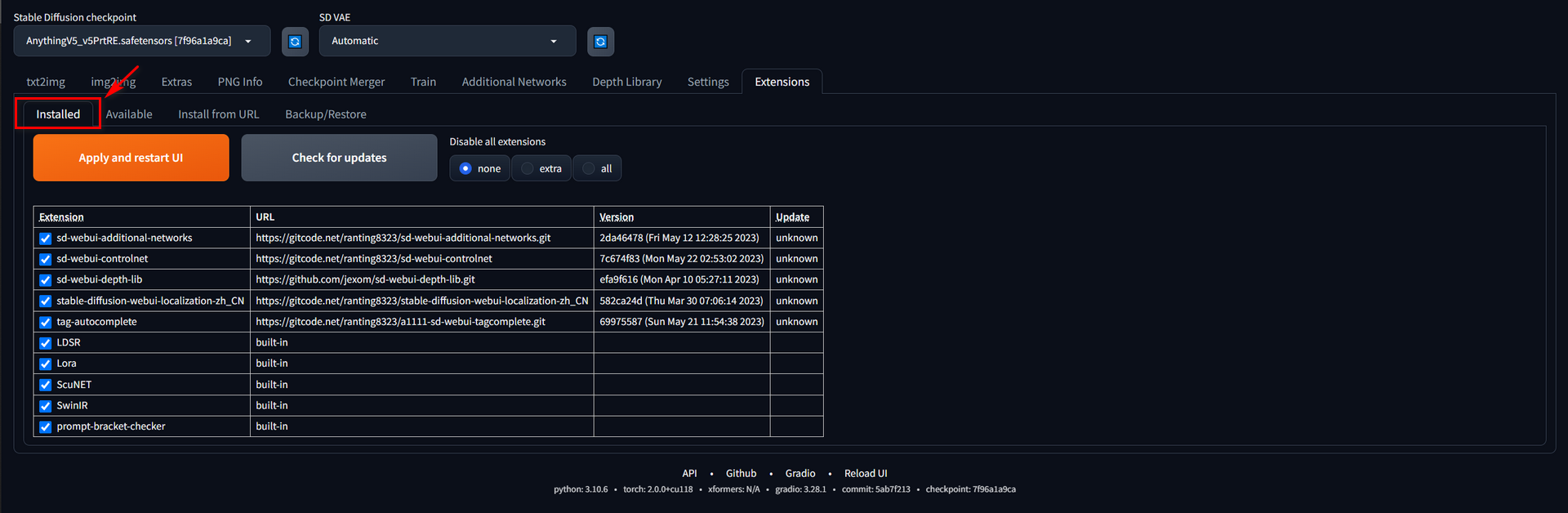
Extensions
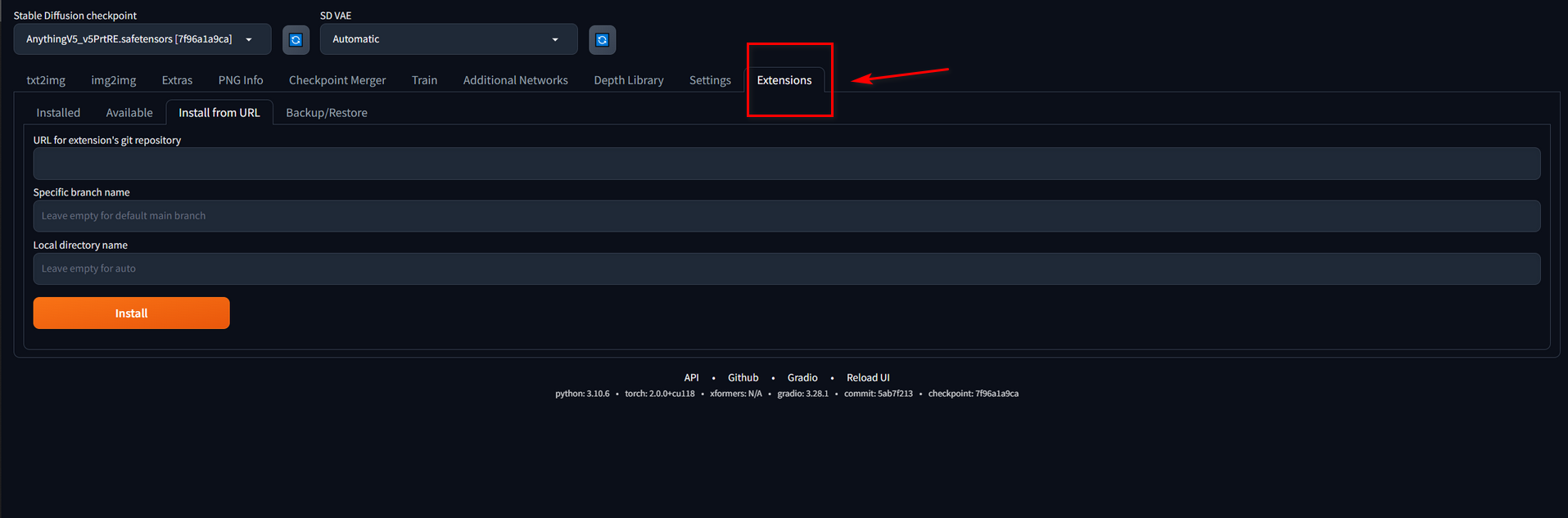
The stable-diffusion Web UI offers excellent plugin support, which enhances the drawing experience by providing various plugins that significantly improve the drawing process. We can get those extensions from its git (it is a tool to manage codes) repository. Besides, here are the extensions I frequently use:
| Extension | URL | Description |
|---|---|---|
| sd-webui-additional-networks | https://gitcode.net/ranting8323/sd-webui-additional-networks.git | This extension is for AUTOMATIC1111’s Stable Diffusion web UI, allows the Web UI to add some networks (e.g. LoRA) to the original Stable Diffusion model to generate images. Currently LoRA is supported. |
| sd-webui-controlnet | https://gitcode.net/ranting8323/sd-webui-controlnet | This extension is for AUTOMATIC1111’s Stable Diffusion web UI, allows the Web UI to add ControlNet to the original Stable Diffusion model to generate images. |
| sd-webui-depth-lib | https://github.com/jexom/sd-webui-depth-lib.git | Depth map library for use with the Control Net extension for Automatic1111/stable-diffusion-webui |
| stable-diffusion-webui-localization-zh_CN | https://gitcode.net/ranting8323/stable-diffusion-webui-localization-zh_CN | Simplified Chinese translation extension , Used for AUTOMATIC1111’s stable diffusion webui |
| tag-autocomplete | https://gitcode.net/ranting8323/a1111-sd-webui-tagcomplete.git | It displays autocompletion hints for recognized tags from “image booru” boards such as Danbooru, which are primarily used for browsing Anime-style illustrations. |
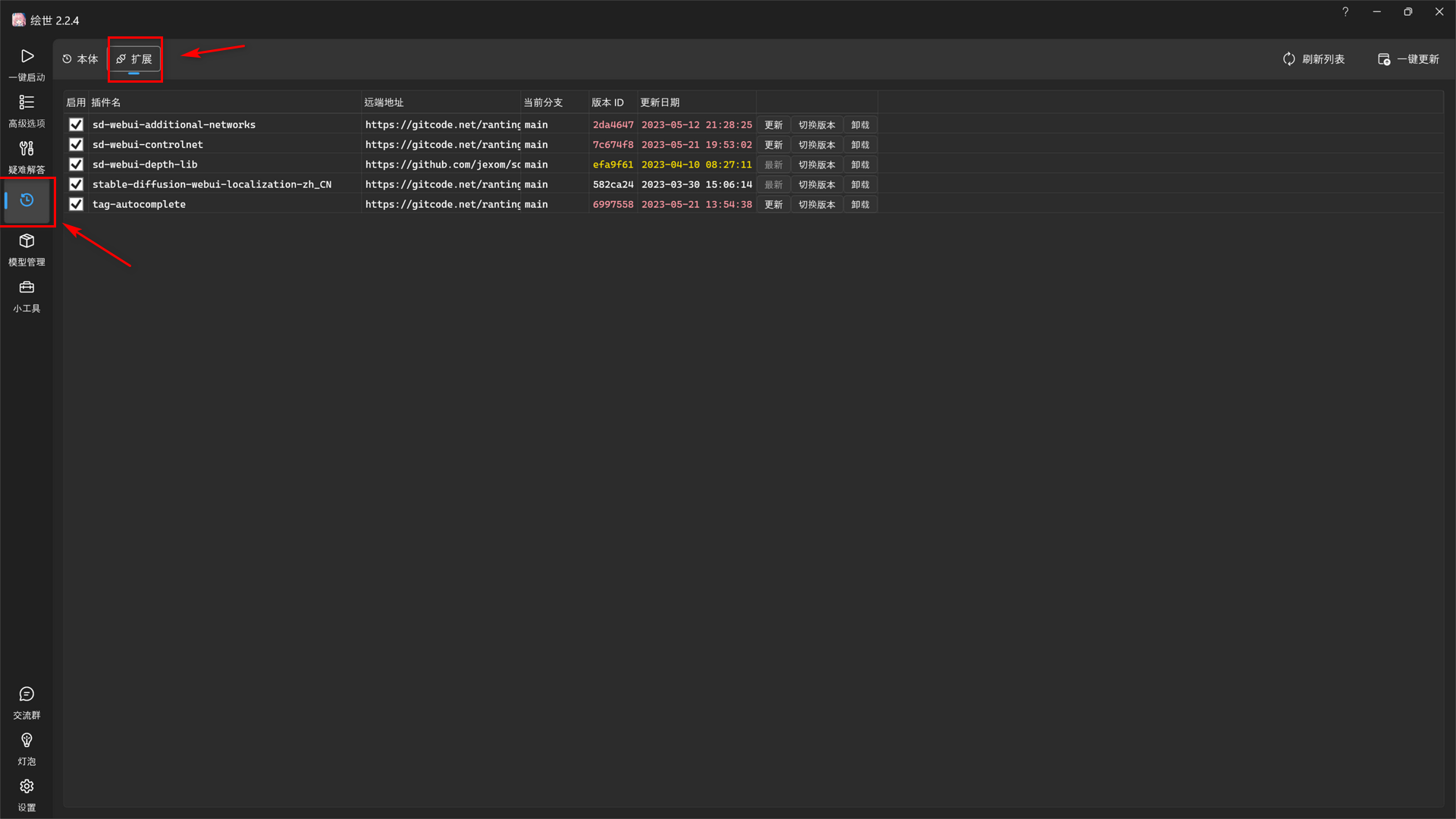
We can manage our extensions in both Web UI and Starter.
My Workflow
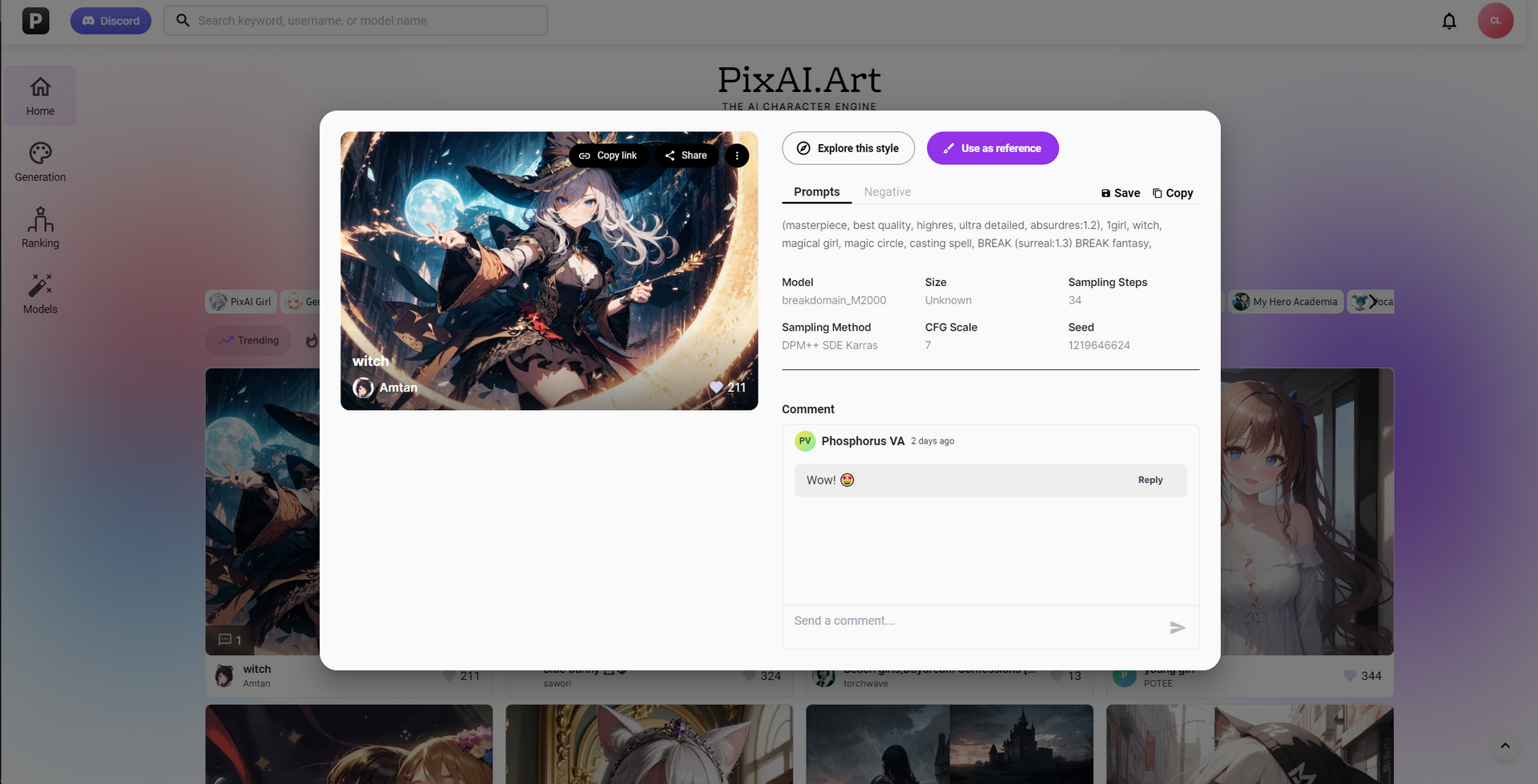
Find prompts
Find an image shared by others.
Make Sample and Change Parameters
Try to generate one image first.
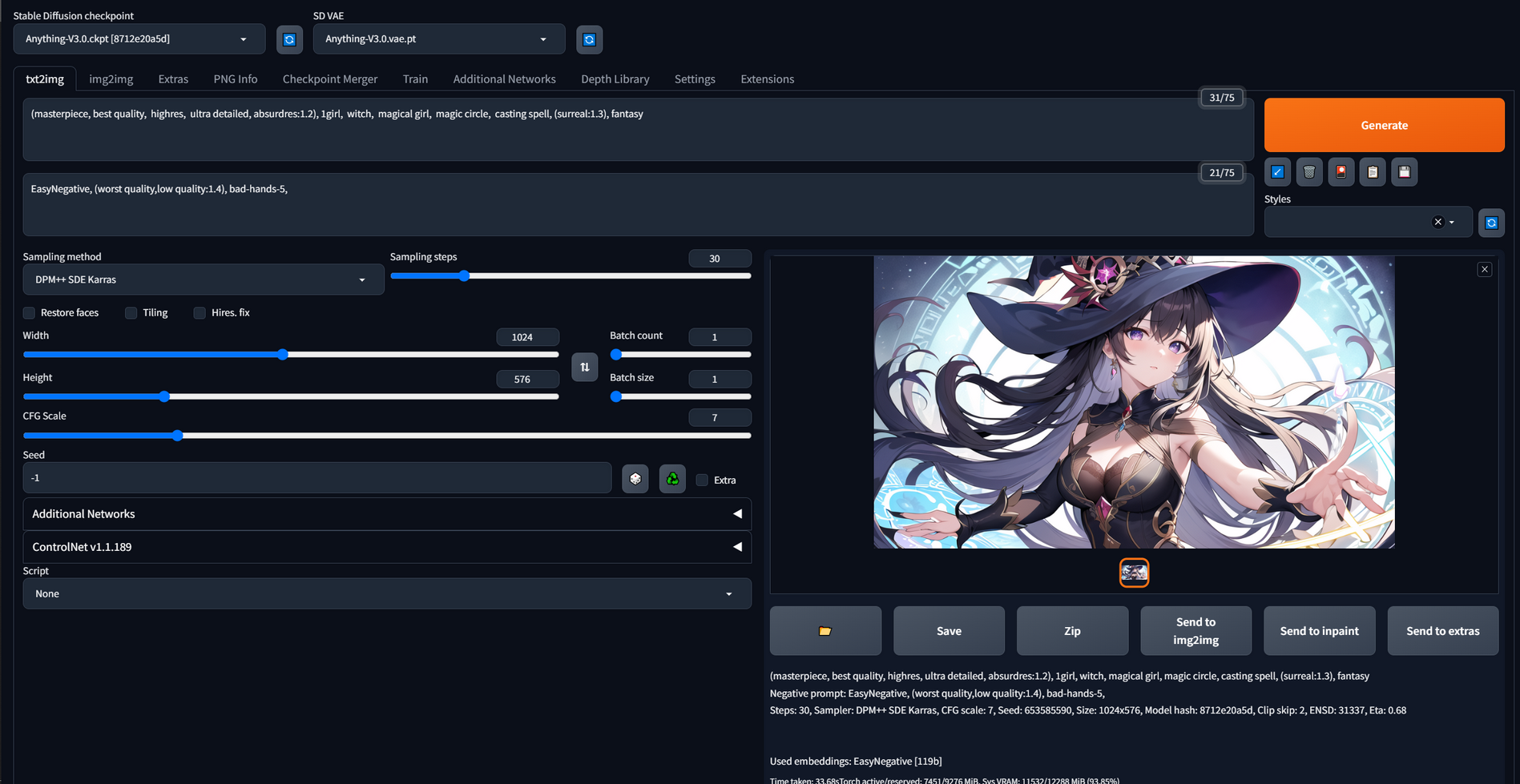
It has a little bit similar to the original image, but it includes less detail. Let’s make some changes.
First, I choose other checkpoints: CounterfeitV25 and AnythingV5. Then, I add some prompts to make the style of those output images more stable. I think these two pictures meet my expectations.
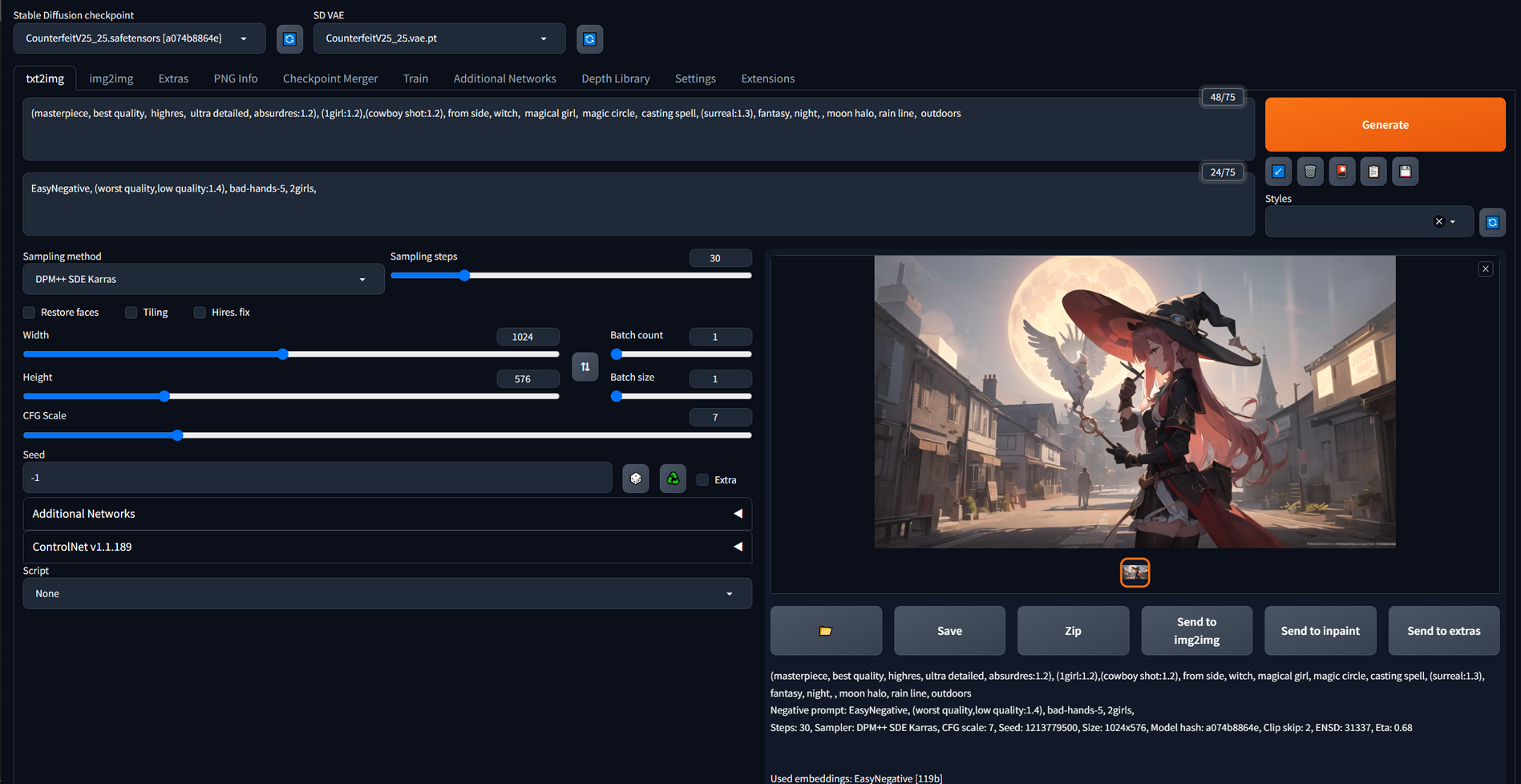 (masterpiece, best quality, highres, ultra detailed, absurdres:1.2), (1girl:1.2),(cowboy shot:1.2), from side, witch, magical girl, magic circle, casting spell, (surreal:1.3), fantasy, night, , moon halo, rain line, outdoors
(masterpiece, best quality, highres, ultra detailed, absurdres:1.2), (1girl:1.2),(cowboy shot:1.2), from side, witch, magical girl, magic circle, casting spell, (surreal:1.3), fantasy, night, , moon halo, rain line, outdoors
Negative prompt: EasyNegative, (worst quality,low quality:1.4), bad-hands-5, 2girls,
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1213779500, Size: 1024x576, Model hash: a074b8864e, Clip skip: 2, ENSD: 31337, Eta: 0.68
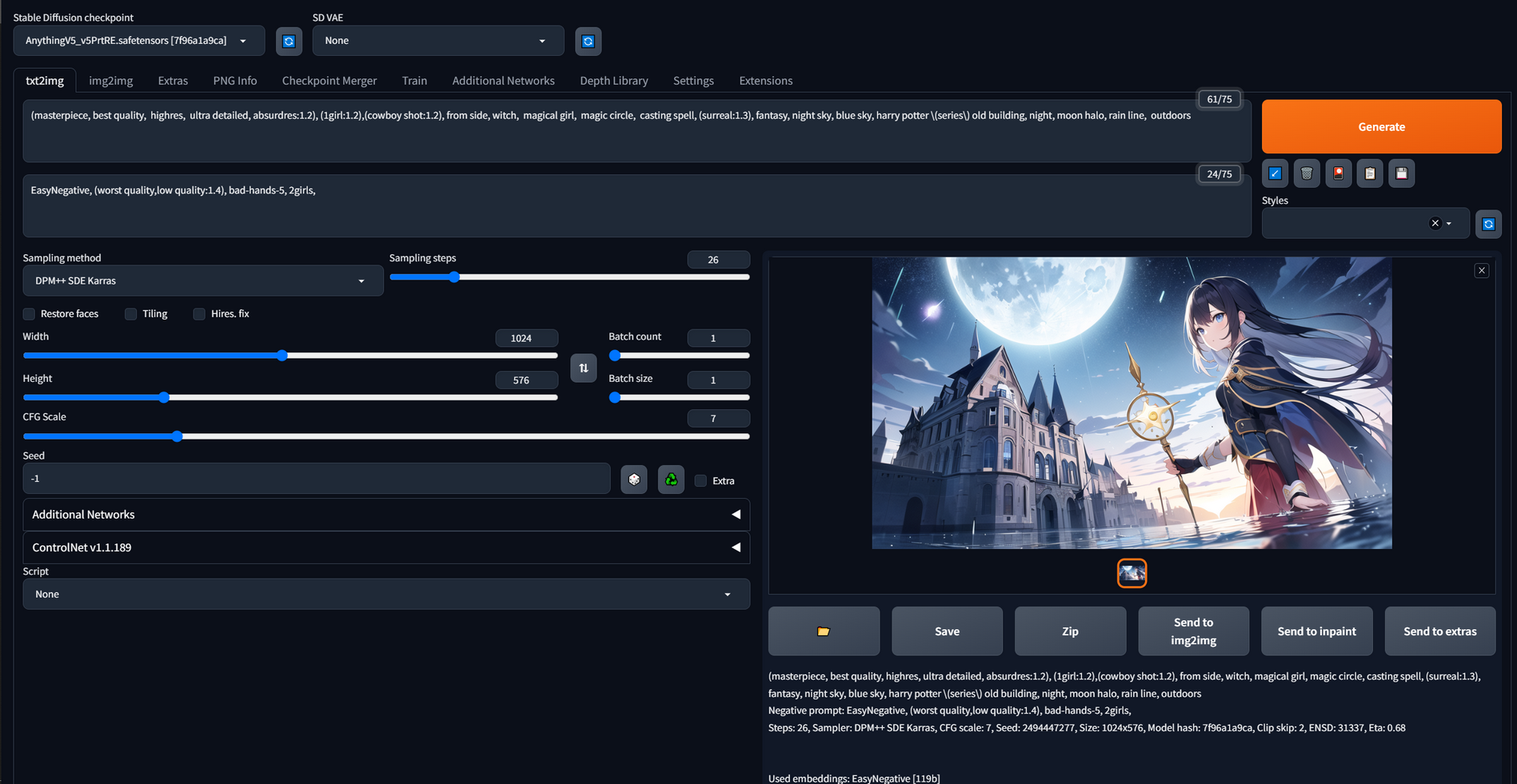 (masterpiece, best quality, highres, ultra detailed, absurdres:1.2), (1girl:1.2),(cowboy shot:1.2), from side, witch, magical girl, magic circle, casting spell, (surreal:1.3), fantasy, night sky, blue sky, harry potter /(series/) old building, night, moon halo, rain line, outdoors
(masterpiece, best quality, highres, ultra detailed, absurdres:1.2), (1girl:1.2),(cowboy shot:1.2), from side, witch, magical girl, magic circle, casting spell, (surreal:1.3), fantasy, night sky, blue sky, harry potter /(series/) old building, night, moon halo, rain line, outdoors
Negative prompt: EasyNegative, (worst quality,low quality:1.4), bad-hands-5, 2girls,
Steps: 26, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2494447277, Size: 1024x576, Model hash: 7f96a1a9ca, Clip skip: 2, ENSD: 31337, Eta: 0.68
Batch Generation
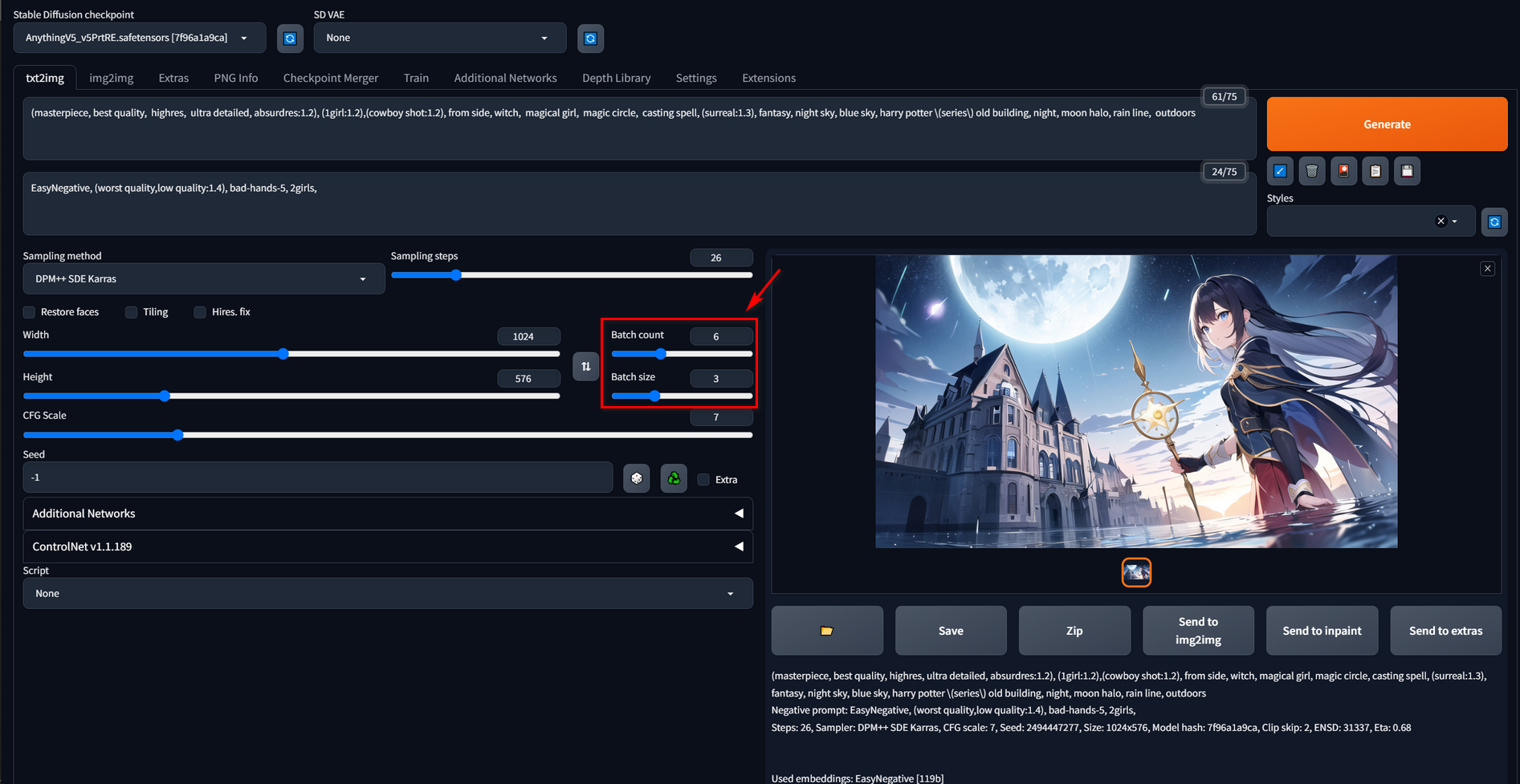
If your VRAM is large enough, you can try a larger number of the Batch size. You can get more information in this post: If you have some VRAM to spare, don’t sleep on the Batch Size setting.
Here are my output images.


Inpaint
Select a few promising pictures, apply a mask, and perform partly retouching. Here, let’s take an example using a single image.
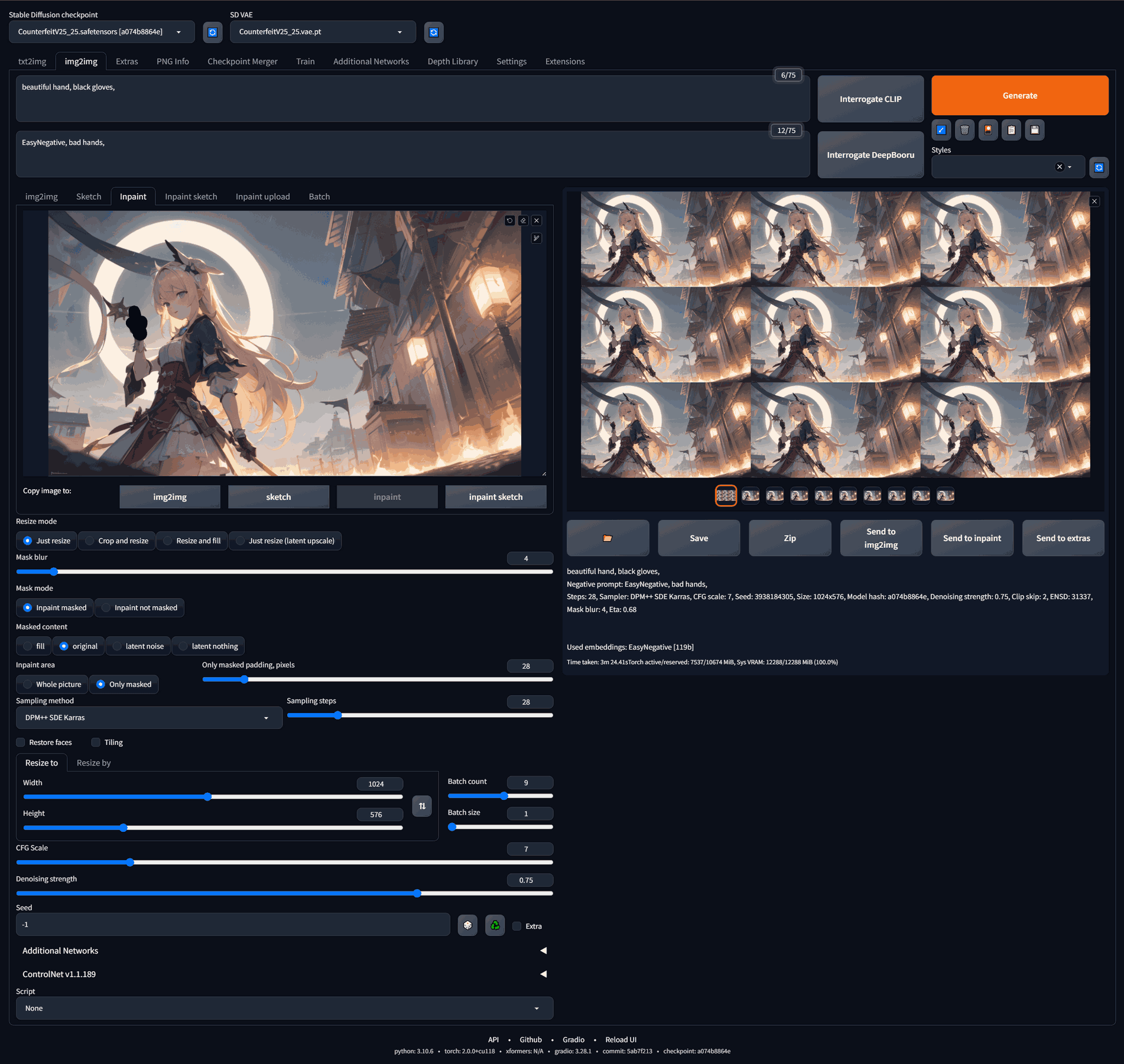
Before:

After:

You can copy my parameters, but there are something to be care of. First, “Stable diffusion checkpoint” and “Resize to” should be the same as the original image. Second, try one image first before batch generation.
Extras
It is the most simple processes in my workflow for its least parameters. I don’t need to explain much about what needs to be done specifically.
About LoRA and ControlNet
I will use the LoRA model when both the art style and character design are well-matched, rather than abusing it. It is a misconception to apply LoRA to any and every image. The same applies to ControlNet as well. It is not suitable for every image. Sometimes, I give AI more creative freedom, but using ControlNet can make the character’s actions or scenes too repetitive. In such cases, I choose to refrain from using ControlNet. For more information about how to use LoRA and ControlNet, please watch the videos uploaded by 秋葉aaaki on Bilibili.
My suggestions
Experiment more
This is what I think is the most important thing. AI has virtually limitless creative potential, and it continues to improve every day. Only by experimenting and trying different approaches can we achieve the desired images. Apart from what I shared above, stable-diffusion has many other things as well. For example, we can redraw human’s hands with the help of sd-webui-depth-lib, which is also something I am currently researching.
Follow some experts
They often share their understanding of AI art and new techniques. Taking myself as an example, I follow 秋葉aaaki on Bilibili, who shares the latest technologies like self-making LoRA and using ControlNet.
At last
Thank you for seeing the end, your browsing is the biggest recognition to me. I would like to emphasize that I am passionate about this field but acknowledge that there is still much for me to learn. If there are any errors in my blog post, please kindly point them out. If there are any copyright issues with the content of my blog, please contact me, and I will promptly make the necessary corrections. Thank you for your understanding and support.